Genetik kod
Genetik kod, genetik malzemede (DNA veya RNA dizilerinde) kodlanmış bilginin canlı hücreler tarafından proteinlere (amino asit dizilerine) çevrilmesini sağlayan kurallar kümesidir. Kod, kodon olarak adlandırılan üç nükleotitlik diziler ile amino asitler arasındaki ilişkiyi tanımlar. Bir nükleik asit dizisindeki üçlü kodon genelde tek bir amino asidi belirler (ancak bazı durumlarda farklı konumlarda bulunan aynı kodon üçlüsü, çevredeki bağlamla ilişkili olarak iki farklı amino asidi kodlayabilir).[1] Genlerin çok büyük çoğunluğu aynı kodla şifrelendiği için (bkz. RNA kodon tablosu), özellikle bu koda kuralsal veya standart genetik kod olarak değinilir, ama aslında pek çok kod varyantı vardır. Yani, standart genetik kod evrensel değildir. Örneğin, insanlarda, mitokondrilerdeki protein sentezi kuralsal koddan farklı bir genetik koda dayalıdır.
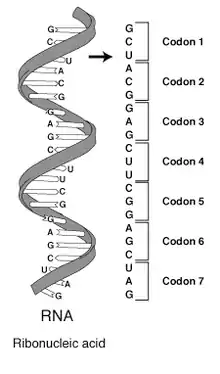
Canlılardaki genetik bilginin yalnızca genetik kod aracılığıyla depolandığı zannedilmemelidir. Tüm organizmaların DNA'sında düzenleyici diziler, genler arası diziler, kromozomal yapı bölgeleri bulunur, bunlar fenotipe büyük oranda katkıda bulunsa da kodon-amino asit ilişkisinden daha farklı kurallar ile etkilerini gösterirler (bakınız epigenetik).
Genetik kodun çözülmesi
DNA'nın yapısı James Watson, Francis Crick, Maurice Wilkins ve Rosalind Franklin tarafından çözüldükten sonra proteinlerin şifrelenmesinin esasını anlamak için ciddi çalışmalar başladı. George Gamow, 20 standart amino asidin kodlanabilmesi için üç harfli bir şifrenin olduğunu önerdi, çünkü 4n'yi en az 20'ye eşit kılan en küçük tam sayı n, 3'dür.
Kodonların üç DNA bazından oluştuğu ilk defa Crick, Brenner ve arkadaşları deneyinde gösterildi. İlk kodon 1961'de ABD Millî Sağlık Enstitüsü'nde (NIH'de) bulunan Marshall Nirenberg ve Heinrich J. Matthaei tarafından çözüldü. Hücresiz bir sistem kullanarak bir poli-urasil molekülünün (yani UUUU... dizisini) çevirisini gerçekleştirdiler ve keşfettiler ki sentezledikleri polipeptit sadece fenilalanin amino asidinden oluşmaktadır. Bu polifenilalanin bulgusundan UUU kodonunun fenilalanin amino asidini kodladığını çıkarsadılar. Bu çalışmayı sürdürerek Nirenberg ve Philip Leder genetik kodun üçlü doğasını ortaya çıkarıp standart genetik koddaki kodonları çözdüler. Bu deneylerde çeşitli mRNA kombinasyonları, üzerinde ribozomlar bulunan bir filtreden geçirilmekteydi. Her bir tekrarlayan üçlü dizisi, özgül taşıyıcı RNA moleküllerinin ribozoma bağlanmasına neden oluyordu. Leder ve Nirenberg bu yolla 64 kodondan 54'ünün dizilerini buldular.
Bunu takiben, Gobind Khorana'nın çalışmaları kodon geri kalanını tanımladı ve kısa süre sonra Robert W. Holley, çeviriyi mümkün kılan adaptör molekül olan taşıyıcı RNA'nın yapısını çözdü. Bu çalışma, Severo Ochoa'nın daha evvelki çalışmalarına dayanmaktaydı; Ochoa, RNA sentezinin enzimolojisi üzerindeki çalışmalarından dolayı 1959'da Nobel ödülü almıştı. 1968'de Khorana, Holley ve Nirenberg çalışmalarına için Nobel Fizyoloji veya Tıp Ödülünü kazandılar.
Genetik kod ile bilgi transferi
Bir organizmanın genomu onun DNA'sında (bazı virüslerde ise RNA'sında) kayıtlıdır. Bir genomun protein veya RNA kodlayan bölümleri genleri oluşturur. Proteinleri kodlayan genler kodon olarak adlandırılan üç nükleotitlik birimlerden oluşur, bunların her biri bir amino asit kodlar. Her nükleotit bir fosfat, bir deoksiriboz şeker ve dört çeşit azotlu bazın birinden oluşur. Pürin türevi bazlar olan adenin (A) ve guanin (G) iki aromatik halkadan oluşur. Pirimidin türevi bazlar olan sitozin (C) ve timin (T) daha küçük olup tek bir aromatik halkadan oluşurlar. DNA'nın çifte sarmallı biçiminde, baz eşleşmesi denen bir yolla, DNA'nin iki ipliği hidrojen bağları ile birbirine bağlanır. Bu bağlar hemen her zaman bir iplikteki adenin bazı ile öbüründeki timin bazı ve bir iplikteki sitozin bazı ile öbüründeki guanin arasında oluşur. Bu demektir ki bir çifte sarmaldaki A ve T bazlarının sayısı eşit olmalıdır, C ve G bazlarının sayısının birbirine eşit olması gerektiği gibi. RNA'da timin (T) yerine urasil (U) bulunur, deoksiriboz yerine de riboz vardır.
Her protein kodlayıcı gendeki baz dizisi transkripsiyon yoluyla DNA'ya benzer özellikleri olan bir RNA polimerine yazılır, bu moleküle mesajcı RNA veya mRNA denir. Mesajci RNA'daki baz dizisi de, sırası gelince, ribozomlar üzerinde translasyon (çeviri) denen süreç ile bir amino asit dizisine, yani bir proteine dönüştürülür. Çeviri süreci, amino asitler için spesifik olan taşıyıcı RNA'lar (tRNA'lar) gerektirir, proteine eklenecek amino asitler bunlara kovalent olarak bağlıdır. Çeviri için ayrıca, enerji kaynağı olarak guanozin trifosfat ve bir takım çeviri faktörleri gereklidir. Her tRNA'nın üzerinde, mRNA'da bağlandığı kendine has kodona komplemanter olan bir antikodon bulunur. tRNA'nın CCA dizisi ile sonlanan 3' ucuna amino asitler kovalent olarak "yüklenirler". Her bir tRNA'ya aminoasil tRNA sentetaz olarak adlandırılan enzimler tarafından spesifik bir amino asit yüklenir, bu enzimlerin hem yükledikleri amino aside hem de tRNA'ya yüksek derecede özgüllükleri vardır. Yüksek özgüllük, protein çevirisindeki hata oranının düşüklüğünü mümkün kılar.
Üç nükleotitli bir kodon ile 4³ = 64 farklı kodon kombinezonu mevcuttur; 64 kodonun hepsi çeviri sürecinde bir amino aside ya da bir bitiş sinyaline karşılık gelir. Eğer, örneğin, UUUAAACCC gibi bir RNA dizisinin okuma çerçevesi birinci U ile başlıyorsa (konvansiyon gereği dizideki bazlar 5' - 3' doğrultusunda yazılır), bu dizide üç kodon vardır, bunlar UUU, AAA ve CCC'dir, her biri bir amino aside karşılık gelir. Bu RNA dizisi, üç amino asit uzunluğunda bir amino asit dizisine çevrilecektir. Bilgisayar bilmi ile bir karşılaştırma yapılacak olursa, bir kodon, veri işlenmesinde kullanılan bir "paket" olmasından dolayı, bir sözcük gibidir, bir nükleotit ise, en küçük veri birimi olmasından dolayı, bir bit gibidir. (Pratikte, tipik bir bilgisayarda, bir nükleotidi temsil etmek için en az iki bit, bir kodon içinde 6 bit gerekir.)
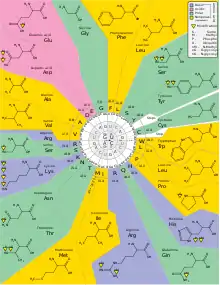
Standart genetik kod aşağıdaki tablolarda gösterilmiştir. Tablo 1, 64 kodonun her birinin hangi amino aside karşılık geldiğini göstermektedir. Tablo 2 ise 20 standart amino asidin her birinin hangi kodona karşılık geldiğini göstermektedir. Bunlar sırasıyla ileri ve geri kodon tablosu olarak adlandırılırlar. Örneğin AAU kodonu asparagin amino asidini kodlar, UGU ve UGC de sisteini kodlar (standart üç harfli gösterimle Asn ve Cys, sırasıyla).
Genetik kod transferi :
RNA kodon tablosu
| apolar | polar | bazik | asidik | (Dur kodonu) |
| İkinci baz | |||||
|---|---|---|---|---|---|
| U | C | A | G | ||
| Birinci baz |
U | UUU (Phe/F) Fenilalanin UUC (Phe/F) Fenilalanin |
UCU (Ser/S) Serin UCC (Ser/S) Serin |
UAU (Tyr/Y) Tirozin UAC (Tyr/Y) Tirozin |
UGU (Cys/C) Sistein UGC (Cys/C) Sistein |
| UUA (Leu/L) Lösin | UCA (Ser/S) Serin | UAA Okra (Dur) | UGA Opal (Dur) | ||
| UUG (Leu/L) Lösin | UCG (Ser/S) Serin | UAG Amber (Dur) | UGG (Trp/W) Triptofan | ||
| C | CUU (Leu/L) Lösin CUC (Leu/L) Lösin |
CCU (Pro/P) Prolin CCC (Pro/P) Prolin |
CAU (His/H) Histidin CAC (His/H) Histidin |
CGU (Arg/R) Arginin CGC (Arg/R) Arginin | |
| CUA (Leu/L) Lösin CUG (Leu/L) Lösin |
CCA (Pro/P) Prolin CCG (Pro/P) Prolin |
CAA (Gln/Q) Glutamin
CAG (Gln/Q) Glutamin |
CGA (Arg/R) Arginin CGG (Arg/R) Arginin | ||
| A | AUU (Ile/I) İzolösin AUC (Ile/I) İzolösin |
ACU (Thr/T) Treonin ACC (Thr/T) Treonin |
AAU (Asn/N) Asparagin AAC (Asn/N) Asparagin |
AGU (Ser/S) Serin AGC (Ser/S) Serin | |
| AUA (Ile/I) İzolösin | ACA (Thr/T) Treonin | AAA (Lys/K) Lizin | AGA (Arg/R) Arginin | ||
| AUG (Met/M) Metiyonin, Başla |
ACG (Thr/T) Treonin | AAG (Lys/K) Lizin | AGG (Arg/R) Arginin | ||
| G | GUU (Val/V) Valin GUC (Val/V) Valin |
GCU (Ala/A) Alanin GCC (Ala/A) Alanin |
GAU (Asp/D) Aspartik asit GAC (Asp/D) Aspartik asit |
GGU (Gly/G) Glisin GGC (Gly/G) Glicin | |
| GUA (Val/V) Valin GUG (Val/V) Valin |
GCA (Ala/A) Alanin GCG (Ala/A) Alanin |
GAA (Glu/E) Glutamik asit GAG (Glu/E) Glutamik asit |
GGA (Gly/G) Glisin GGG (Gly/G) Glisin | ||
- not1^ AUG kodonu hem metiyonini kodlar hem de başlama konumunu işaretler: mRNA'nın ilk AUG'si proteine çevirinin başladığı yeri belirler.
| Ala/A | GCU, GCC, GCA, GCG | Leu/L | UUA, UUG, CUU, CUC, CUA, CUG |
|---|---|---|---|
| Arg/R | CGU, CGC, CGA, CGG, AGA, AGG | Lys/K | AAA, AAG |
| Asn/N | AAU, AAC | Met/M | AUG |
| Asp/D | GAU, GAC | Phe/F | UUU, UUC |
| Cys/C | UGU, UGC | Pro/P | CCU, CCC, CCA, CCG |
| Gln/Q | CAA, CAG | Ser/S | UCU, UCC, UCA, UCG, AGU, AGC |
| Glu/E | GAA, GAG | Thr/T | ACU, ACC, ACA, ACG |
| Gly/G | GGU, GGC, GGA, GGG | Trp/W | UGG |
| His/H | CAU, CAC | Tyr/Y | UAU, UAC |
| Ile/I | AUU, AUC, AUA | Val/V | GUU, GUC, GUA, GUG |
| BAŞLAMA | AUG | DURDURMA | UAG, UGA, UAA |
Belirgin özellikler
Dizinin okuma çerçevesi
Bir kodon çevirinin başladığı ilk nükleotit ile tanımlanır. Örneğin GGGAAACCC dizisi, eğer ilk bazdan itibaren okunursa, GGG, AAA ve CCC kodonlarından oluşur; ve eğer ikinci bazdan itibaren okunursa GGA ve AAC kodonlarından, eğer üçüncü bazdan itibaren okunursa GAA ve ACC kodonlarından oluşur (kısmî kodonlar göz ardı edilmiştir). Dolayısıyla her dizi üç farklı okuma çerçevesi ile okunabilir, her biri farklı amino asit dizileri üretir (verilen örnekte, sırasıyla, Gly-Lys-Pro, Gly-Asp, veya Glu-Thr). Çift iplikli DNA ile 6 olası okuma çerçevesi vardır, üçü bir iplik üzerinde ileri yönde, üçü öbür iplikte ters yöndedir.
Bir protein dizisinin çevirisinin yapıldığı asıl çerçeve başlama kodonu tarafından belirlenir, bu genelde mRNA disindeki ilk AUG kodonudur. Üçün katı olmayan sayıda nükleotidin eklenmesi veya çıkmasına neden olan mutasyonlar, okuma çerçevesini bozar, bu tip mutasyonlara okuma çerçeve kayma mutasyonu denir. Bu mutasyonlar, ortaya çıkan proteinin işlevini bozabilir (eğer protein oluşabilirse) ve bu yüzden canlı hücrelerdeki protein kodlayıcı dizilerde ender görülürler. Çoğu zaman bu kötü oluşmuş proteinler proteolitik yıkıma yollanırlar. Ayrıca, bir çerçeve kayma mutasyonu yüksek olasılıkla bir dur kodonunun okunmasına neden olur, bu da proteini erken sonlandırır.[2] Çerçeve kayma mutasyonlarının kalıt olma enderliğinin bir nedeni, eğer çevrilen protein selektif şartlarda büyümek için gerekli ise, işlevsel bir proteinin yokluğunun organizma için ölümcül olabilmesidir.
Başlama ve durma kodonları
Çeviri, bir zincir başlama kodonu ile başlar. Dur kodonundan farklı olarak, bu kodon çevirinin başlaması için yeterli değildir. Civardaki diziler (örneğin E. coli'de Shine-Dalgarno dizisi) ve başlama faktörleri de başlama için gereklidir. En yaygın başlama kodonu AUG'dir, bu kodon metiyonin olarak, veya bakterilerde formilmetiyonin olarak çevirilir.[3]
Üç dur kodonuna adlar verilmiştir: UAG, amber, UGA, opal ve UAA, okra (İng. ochre). Amber adı, onu keşfeden Richard Epstein ve Charles Steinberg tarafından, arkadaşları Harris Bernstein anısına verilmişti, çünkü soyadı Almanca "amber" (kehribar rengi) anlamına gelmekteydi. Ardından, diğer dur kodonları, renk temasını sürdürmek için "okra" (koyu sarı) ve "opal" olarak adlandırıldı. Dur kodonları "bitiş" veya "anlamsız" kodon olarak da adlandırılırlar. Bitiş kodonları, kendilerine bağlanacak bir tRNA'nın yokluğu nedeniyle bağlanan salma faktörleri (İng. release factor) büyüyen polipeptit zincirinin ribozomdan serbest bırakılmasını neden olur.[4]
Genetik kodun dejenerliği
Genetik kodda artıklık (ing. redundancy) vardır ama muğlaklık yoktur (tam bağıntı için yukarıda #RNA kodon tablosu;kodon tablolarına bakın. Örneğin, GAA ve GAG kodonlarının her ikisi de glutamik asidi belirlese de (artıklık), her ikisi de başka bir amino asidi kodlamaz (muğlaklık). Bir amino asidi kodlayan kodonlar her üç pozisyonda da farklılık gösterebilir. Örneğin, glutamik asit amino asidi GAA ve GAG kodonları tarafından belirlenir (3. pozisyonda faklılık), lösin UUA,UUG, CUU, CUC, CUA, CUG kodonları tarafından belirlenir (1. ve 3. pozisyonda farklılık), serin ise UCA, UCG, UCC, UCU, AGU, AGC kodonları tarafından belirlenir (1., 2. ve 3. pozisyonlarda farklılık).
Bir kodondaki bir pozisyonda herhangi bir nükleotit olsa da aynı amino asidi kodlanıyorsa o pozisyon için dört misli dejenere konum terimi kullanılır. Örneğin, glisin kodonlarının (GGA, GGG, GGC, GGU) 3. pozisyonu dört misli dejenere bir konumdur, çünkü bu pozisyondaki her bir nükleotit yer değişimi eş anlamlıdır, kodlanan amino asidi değiştirmezler. Bazı kodonların sadece 3. pozisyonu dört misli dejenere olabilir. Bir kodondaki bir pozisyona dört bazdan sadece ikisinin gelmesi ile aynı amino asit kodlanıyorsa o pozisyon için iki misli dejenere terimi kullanılır. Örneğin glutamik asit kodonlarının (GAA, GAG) 3. pozisyonu iki misli dejenere bir konumdur. İki misli dejenere konumlarda eşdeğer nükleotitler ya iki pürin (A/G) veya iki pirimidin (C/U) olur, dolayısıyla sadece transversiyonlu yer değişimler (pürinden pirimidine veya pirimidinden pürine) eşanlamlı olmaz. Bir kodondaki pozisyondaki herhangi bir mutasyon bir amino asit değişimine neden olursa o pozisyon dejenere olmayan konum olarak değinilir. Üç misli dejenere konum olan tek bir kodon vardır, bu izolösin kodonunun 3. pozisyonudur: AUU, AUC, or AUA izolösin kodlar ama AUG metiyonin kodlar.
Altı kodon tarafından kodlanan üç amino asit vardır: serin, lösin ve arginin. Sadece iki amino asit tek bir kodon tarafından belirlenir, bunlardan biri, hem metiyonin hem de başlamayı kodlayan AUG'dir, öbürü UGG tarafından kodlanan triptofandır. Genetik koddaki dejenerelik, eşanlamlı mutasyonları mümkün kılar.
Dejenereliğin nedeni, üçlü kodun 20 amino asit ve bir stop kodon belirlemesidir. Dört baz olduğu için en az 21 kodu oluşturmak için üçlü kodonlar gereklidir. Örneğin, kodon başına iki baz olsaydı, 16 tane amino asit kodlanabilirdi (4²=16). En az 21 kod gerektiği için 4³ = 64 olası kodon verir, yani kodda belli bir dejenerlik bulunması gerekir.
Genetik kodun bu özellikleri noktasal mutasyonlarda onu hataya daha tolaranslı yapar. Örneğin, teorik olarak, dört misli dejenere kodonlar üçüncü pozisyonda bir mutasyona dayanıklı olmaları beklenebilir (ama gerçekte kodon kullanım yanlılığı (İng. codon usage bias) çoğu organizmada bunu sınırlar). Keza, iki misli dejenere kodonlar 3. pozisyonda olabilecek 3 mutasyondan birine dayanıklıdırlar. Geçiş (transisyon) mutasyonları (pürinden pürine, veya pirimidinden pirimidine mutasyonlar) dönüşüm (transversiyon) mutasyonlarından (pürinden pirimidine veya tersi) daha sık olduğu için iki misli dejenere konumlarda pürinlerin veya pirimidinlerini birbirine denk olması, hata toleransını daha da artırır.
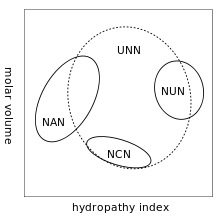
Artıklık özelliğinin bir sonucu, bazı mutasyonların sadece sessiz mutasyonlara yol açması, diğer bazı mutasyonlarda ise, değişen amino asidinin hidrofiliklik veya hidrofobikliğinin aynı olmasından dolayı, proteinin etkilenmemesidir. Örneğin, NUN şeklinde bir kodon (N = herhangi bir nükleotit) genelde hidrofobik amino asitleri kodlar; NCN küçük boyutlu ve orta derecede hidrofobik amino asitler kodlar; NAN orta büyüklüklü hidrofobik amino asitler kodlar; UNN hidrofilik olmayan amino asitler kodlar.[5][6]
Yukarıda belirtilen bu genel eğilimlere rağmen noktasal bir mutasyon bozuk bir proteine neden olabilir. Mutant hemoglobinde hidrofilik glutamat (Glu), hidrofobik valin (Val) ile yer değiştirmiştir, yani GAA veya GAG'nin yerini GUA veya GUG almıştır. Glutamatın valinle değişmesi beta globulin'in çözünürlüğünü azaltır, bunun sonucu olarak hemoglobin lineer polimerler oluşturur. Değişmiş olan valinler arasındaki hidrofobik etkileşimlerin neden olduğu bu polimerleşme ile alyuvarlarda orak hücre deformasyonu meydana gelir.
64 kodona karşılık çoğu organizmada sadece 40-50 tRNA tipi vardır.[7] Bazı tRNA'ların birden çok kodona bağlanabilmesinin nedeni, tRNA antikodonundaki birinci bazın değişime uğramış olması ve bu bazın "oynak" olmasından dolayı oynak baz çifti oluşturabilmesidir. Değişime uğramış olan baz inozindir, ayrıca G-U bazları birbirleriyle Watson-Crick kurallarına uymayan bir baz çifti oluşturabilirler.
Standart genetik kodun çeşitlemeleri
Standart kodda ufak variyasyonların olduğu tahmin edilmiş olmakla beraber,[8] bunların keşfedilmesi 1979'u buldu. O yıl, insan mitokondri genleri üzerinde çalışan araştırmacılar mitokondrilerin alternatif bir kod kullandığını buldular.[9] O zamandan beri alternatif mitokondrial genetik kodlar[10] dahil olmak üzere pek çok başka varyant bulunmuştur,[11]. Bazı faklılıklar ufaktır, örneğin mikoplazmalarda UGA triptofan olarak çevrilir. Bazı ender durumlarda bazı proteinlerin o türde normal olarak kullanılmayan alternatif başlama kodonları kullanabildiği bulunmuştur.[12]
Bazı proteinlerde standart dur kodonunun yerine standart olmayan amino asitler gelir, bunun belirleyicisi mRNA'da bu kodonun yakınında bulunan sinyal dizileridir: UGA selenosistein kodlar, UAG de pirolizin kodlar. Selenosistein ve pirolizin artık 21. ve 22. standart amino asit olarak sayılmaktadır. Genetik koddaki varyasyonların ayrıntıları NCBI web sitesinde11 Aralık 2015 tarihinde Wayback Machine sitesinde arşivlendi. görülebilir.
Bu farklılıklara rağmen tüm bilinen kodlar büyük benzerlikler gösterirler ve tüm organizmalarda işleyen temel mekanizma aynıdır: üç bazlı kodonlar, tRNA, ribozomlar, kodonların okunma yönü ve nükleotit dizisinin üçer harfler olarak okunup bir amino asit dizisi olarak sentezlenmesi.
Genetik kodun kökeni hakkında teoriler
Çeşitliliklere rağmen tüm hayat biçimleri tarafından kullanılan genetik kodlar çok benzerdir. Dünyadaki yaşam tarafından kullanılan genetik kodun yanı sıra pek çok başka genetik kod da olabileceğine göre, mevcut kodun yaşamın oluşum tarihinin en başlarında oluşmuş olması evrim teorisi bakımından muhtemeldir. Taşıyıcı RNA'nın filogenetik analizi, mevcut aminoasil tRNA sentetazlar grubundan oluşumundan önce tRNA'ların evrimleşmiş olduğunu önermektedir.[13]
Genetik kod, kodonların rastgele amino asitlere atamasından ibaret değildir.[14] Örneğin, aynı biyosentetik yolak üzerinde yer alan amino asitlerin kodonlarının ilk bazı aynı olmak eğilimlidir,[15] ve benzer fiziksel özellikleri olan amino asitlerin kodonları da benzerdir.[16][17]
Genetik kodun evrimine dair teorilerde üç ana tema vardır:[18]
- Aptamer deneyleri bazı amino asitlerin kendilerini kodlayan baz üçlülerine karşı seçici bir bağlanma afinitesine sahip olduğunu göstermiştir.[19] Bu bulgunun önerdiği görüş, tRNA ve ilişkili enzimler içeren mevcut karmaşık çeviri mekanizmasının sonradan meydana gelen bir gelişme olduğu, orijinde protien dizilerinin doğrudan baz dizileri üzerinde kalıplandığıdır.
- Standart modern genetik kod daha evvelki basit bir koddan, bir "biyokimyasal genişleme" yoluyla türemiştir. Buradaki fikir, en eski (primordiyal) yaşamın yeni amino asitleri keşfettikçe (örneğin bunlar metabolizma ürünleri olmuş olabilir) bunları genetik kodlama mekanizmasına dahil ettiğidir. Günümüze kıyasla geçmişte daha az sayıda farklı amino asit olduğuna dair pek çok dolaylı delil olsa da,[20] amino asitlerin genetik koda hangi sırayla dahil olduğuna dair ayrıntılı hiptezler çok daha tartışmalı olmuştur.[21][22]
- Doğal seleksiyon, mutasyonların etkisini en aza getirecek yönde kodon atamalarına yol açmıştır.[23]
Kaynakça
- Turanov AA, Lobanov AV, Fomenko DE, Morrison HG, Sogin ML, Klobutcher LA, Hatfield DL, Gladyshev VN (Ocak 2009). "Genetic code supports targeted insertion of two amino acids by one codon". Science. 323 (5911). ss. 259-61. doi:10.1126/science.1164748. PMID 19131629.
- Isbrandt D, Hopwood JJ, von Figura K, Peters C (1996). "Two novel frameshift mutations causing premature stop codons in a patient with the severe form of Maroteaux-Lamy syndrome". Hum. Mutat. 7 (4). ss. 361-3. doi:10.1002/(SICI)1098-1004(1996)7:4<361::AID-HUMU12>3.0.CO;2-0. PMID 8723688.
- Touriol C, Bornes S, Bonnal S; ve diğerleri. (2003). "Generation of protein isoform diversity by alternative initiation of translation at non-AUG codons". Biology of the cell / under the auspices of the European Cell Biology Organization. 95 (3-4). ss. 169-78. PMID 12867081.
- "How nonsense mutations got their names". 16 Kasım 2014 tarihinde kaynağından arşivlendi. Erişim tarihi: 12 Haziran 2009.
- Yang; ve diğerleri. (1990). Reaction Centers of Photosynthetic Bacteria. Springer-Verlag. s. 209-218. " M.-E. Michel-Beyerle. (Ed.) " yazısı görmezden gelindi (yardım)
- "Complexity International". 31 Mart 2015 tarihinde kaynağından arşivlendi. Erişim tarihi: 12 Haziran 2009.
- "Genomic tRNA Database". 30 Mayıs 2015 tarihinde kaynağından arşivlendi. Erişim tarihi: 12 Haziran 2009.
- Crick, FHC, Orgel, LE (1973). "Directed panspermia". Icarus. Cilt 19. ss. 341-346. p. 344: "It is a little surprising that organisms with somewhat different codes do not coexist." (Further discussion at 11 Aralık 2017 tarihinde Wayback Machine sitesinde arşivlendi.)
- Barrell BG, Bankier AT, Drouin J (1979). "A different genetic code in human mitochondria". Nature. Cilt 282. ss. 189-94. PMID 226894.
- Jukes TH, Osawa S (Aralık 1990). "The genetic code in mitochondria and chloroplasts". Experientia. 46 (11-12). ss. 1117-26. PMID 2253709.
- "NCBI: "The Genetic Codes"". 26 Haziran 2015 tarihinde kaynağından arşivlendi.
- "Genetic Code page in the NCBI Taxonomy section". 11 Aralık 2015 tarihinde kaynağından arşivlendi. Erişim tarihi: 12 Haziran 2009.
- De Pouplana, L.R. (1998). "Genetic code origins: tRNAs older than their synthetases?". Proceedings of the National Academy of Sciences. Cilt 95. s. 11295. doi:10.1073/pnas.95.19.11295. PMID 9736730. 9 Mart 2006 tarihinde kaynağından arşivlendi. Erişim tarihi: 12 Haziran 2009.
- Freeland SJ, Hurst LD (1998). "The genetic code is one in a million". J. Mol. Evol. Cilt 47. ss. 238-48. doi:10.1007/PL00006381. PMID 9732450. 15 Eylül 2000 tarihinde kaynağından arşivlendi. Erişim tarihi: 12 Haziran 2009.
- Taylor FJ, Coates D (1989). "The code within the codons". BioSystems. 22 (3). ss. 177-87. doi:10.1016/0303-2647(89)90059-2. PMID 2650752.
- Di Giulio M (Ekim 1989). "The extension reached by the minimization of the polarity distances during the evolution of the genetic code". J. Mol. Evol. 29 (4). ss. 288-93. doi:10.1007/BF02103616. PMID 2514270.
- Wong JT (Şubat 1980). "Role of minimization of chemical distances between amino acids in the evolution of the genetic code". Proc. Natl. Acad. Sci. U.S.A. 77 (2). ss. 1083-6. doi:10.1073/pnas.77.2.1083. PMID 6928661.
- Knight RD, Freeland SJ, Landweber LF (Haziran 1999). "Selection, history and chemistry: the three faces of the genetic code". Trends Biochem. Sci. 24 (6). ss. 241-7. PMID 10366854.
- Knight RD, Landweber LF (Eylül 1998). "Rhyme or reason: RNA-arginine interactions and the genetic code". Chem. Biol. 5 (9). ss. R215-20. PMID 9751648.
- Brooks, DJ; Fresco, JR, Lesk, AM, Singh, M (2002). "Evolution of Amino Acid Frequencies in Proteins Over Deep Time: Inferred Order of Introduction of Amino Acids into the Genetic Code". Molecular Biology and Evolution. Cilt 19. ss. 1645-1655. 13 Aralık 2004 tarihinde kaynağından arşivlendi. Erişim tarihi: 12 Haziran 2009.
- Amirnovin R (Mayıs 1997). "An analysis of the metabolic theory of the origin of the genetic code". J. Mol. Evol. 44 (5). ss. 473-6. PMID 9115171.
- Ronneberg TA, Landweber LF, Freeland SJ (2000). "Testing a biosynthetic theory of the genetic code: fact or artifact?". Proc. Natl. Acad. Sci. U.S.A. Cilt 97. ss. 13690-5. doi:10.1073/pnas.250403097. PMC 17637 $2. PMID 11087835.
- Freeland SJ, Wu T, Keulmann N (2003). "The case for an error minimizing standard genetic code". Orig Life Evol Biosph. Cilt 33. ss. 457-77. PMID 14604186.
Ek okuma
- Griffiths, Anthony J.F.; Miller, Jeffrey H.; Suzuki, David T.; Lewontin, Richard C.; Gelbart, William M. (1999). Introduction to Genetic Analysis (7th ed.)5 Şubat 2005 tarihinde Wayback Machine sitesinde arşivlendi.. New York: W. H. Freeman & Co. ISBN 0-7167-3771-X
- Alberts, Bruce; Johnson, Alexander; Lewis, Julian; Raff, Martin; Roberts, Keith; Walter, Peter. (2002). Molecular Biology of the Cell (4th ed.)3 Ekim 2009 tarihinde Wayback Machine sitesinde arşivlendi.. New York: Garland Publishing. ISBN 0-8153-3218-1
- Lodish, Harvey; Berk, Arnold; Zipursky, S. Lawrence; Matsudaira, Paul; Baltimore, David; Darnell, James E. (1999). Molecular Cell Biology (4th ed.)23 Şubat 2005 tarihinde Wayback Machine sitesinde arşivlendi.. New York: W. H. Freeman & Co. ISBN 0-7167-3706-X
Dış bağlantılar
- The Genetic Codes → Genetic Code Tables 1 Haziran 2009 tarihinde Wayback Machine sitesinde arşivlendi.
- DNA → Amino Acid çeviricisi
- DNA → Protein dizi çeviricisi
- DNAdan proteine çeviri (6 çerçeve/17'den fazla genetik kod) 8 Haziran 2009 tarihinde Wayback Machine sitesinde arşivlendi.
- The Codon Usage Database 14 Haziran 2009 tarihinde Wayback Machine sitesinde arşivlendi. Çeşitli organzmalar için kodon sıklık tabloları
- Genetik kodda bulunan simetriler30 Mart 2010 tarihinde Wayback Machine sitesinde arşivlendi.
