OpenMP
OpenMP Solaris, IBM AIX , HP-UX, GNU/LINUX, MAC OS X ve Windows işletim sistemleri üzerinde çoğu işlemci mimarisi üzerinde Fortran, C++, C programlama dillerinde çoklu platform paylaşımlı bellek çoklu işlemeyi destekleyen bir uygulama geliştirme arayüzüdür, yani bir API'dir. OpenMP derleyici yönergelerinin kütüphane rutinlerini ve ortam değişkenlerinin çalışma zamanı davranışını etkileyen bir kümesini içerir.
 | |
| Geliştirici(ler) | OpenMP Architecture Review Board[1] |
|---|---|
| Güncel sürüm | 3.1[2] / 9 Temmuz 2011) |
| Programlama dili | C, C++, Fortran |
| İşletim sistemi | Çapraz platform yazılımları |
| Platform | Çapraz platform yazılımları |
| Tür | UPA |
| Lisans | Various[3] |
| Resmî sitesi | openmp.org |
OpenMP kâr amacı gütmeyen, OpenMp Archtecture Review Board(OpenMP ARB) isimli uluslararası bir birlik tarafından yönetilir. Bu birliğin çoğunluğu yazılım satıcıları AMD, IBM, Intel, Cray, HP, Fujitsu, Nvidia, NEC, Microsoft, Texas Intstruments, Oracle Corporation şirketlerinden ve bilgisayar donanım grupları tarafından oluşur.
OpenMP standart masaüstü bilgisayarlarda süper bilgisayarlara varana kadar paralel uygulamaları geliştirmek için programcılara basit ve uygun bir arayüz veren ölçeklenebilir ve taşınabilir bir model kullanır.
Paralel programlamanın melez bir modeliyle oluşturulmuş bir uygulama hem OpenMP hem de MPI kullanarak bir bilgisayar üzerinde çalışabilir ya da paylaşımsız bellek sistemleri için OpenMP'nin gelişmiş sürümlerini kullanarak kullanıcıdan daha da bağımsız çalışabilir.
Giriş
OpenMP çoklu iş parçacığı gerçekleştirimidir. Çoklu iş parçacığı ana iş parçacığının(sırasıyla yürütülen komutların bir dizisi) belirli bir sayıda yardımcı iş parçacıklarını durdurması ve bir görev onlar arasında paylaştırması olan paralelleştirme metodudur. İş parçacıkları birbiri ardında paralel şekilde çalışırlar. Farklı işlemcilerin iş parçacıkları farklı çalışma zamanı ortamlarını kendilerine tahsis ederler.
Paralel çalışacak olan kodun bir bölümü sırasıyla işaretlenir. Bu işaretleme kod bölümünün yürütülmesinden önce iş parçacıklarının o kod bölümüne girmelerine sebep olacak ön işlemci direktifleridir. Her bir iş parçacığı onlara bağlı bir ID'ye sahiptir. omp_get_thread_num()fonksiyonu ile bu ID elde edilir.İş parçacığı ID'si bir tam sayıdır ve ana iş parçacığının ID'si sıfırdır. Paralelleştirilmiş kodun yürütülmesinden sonra iş parçacıkları ana iş parçacığına tekrar geri katılırlar. Programın sonuna kadar bu böyle devam eder.
Varsayılan olarak her bir iş parçacığı kodun paralelleştirilmiş bölümünü birbirinden bağımsız şekilde yürütür. İş paylaşımı yapıları iş parçacıkları arasında bir görevi paylaştırmak için kullanılabilir, böylece her bir iş parçacığı kodun kendisine ayrılan bölümünde çalışır. Hem görev paralelleştirme hem de veri paralelleştirme OpenMP kullanarak bu yöntemle yapılır.
Çalışma zamanı ortamı kullanıma bağlı olarak işlemcilere iş parçacığı tahsis eder, makine yükleme ve diğer faktörler gibi. İş parçacıklarının sayısı ortam değişkenleri veya kod içerisinde kullanılan fonksiyonlara bağlı olarak çalışma zamanı ortamı tarafından atanır. OpenMP fonksiyonları omp.h etiketli C/C++ header dosyaları ile programa dahil edilir.
Tarihçe
OpenMP ARB ilk arayüz programını Fortran 1.0 için Ekim 1997 OpenMP ile yayınladı. Bir sonraki yıl C/C++ standartını piyasaya sürdüler. Fortran ve C/C++ 2.0 versiyonları ile birlikte 2002 yılında piyasaya sürüldü. 2.5 versiyonu C/C++ Fortranın bir kombinasyonu olarak 2005 yılında piyasaya sürüldü.
Mayıs 2008'de 3.0 versiyonu piyasaya sürüldü. Yeni özellikler görevler ve görev yapıları kavramları versiyonu 3.0'a dahil edildi.
Versiyon 3.1 9 Temmuz 2011'de piyasaya sürüldü.
Versiyon 4.0'ın 2013 Haziran veya Temmuz aylarında sunulması bekleniyor. Aşağıdaki özellikleri geliştirmiş ve kendisine eklemiştir. Hızlandırıcılar içi destek, atomikler, hata yönetimi,işparçacığı ilişkisi, görev geliştirimi, kullanıcı tanımlı arttırma, SIMD desteği, Fortran 2003 desteği.
Temel elemanlar
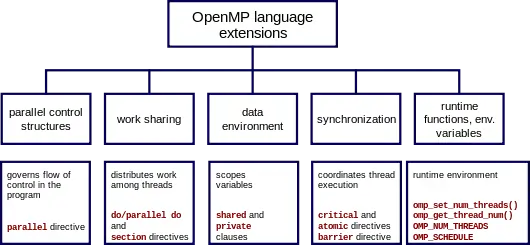
OpenMP temel elemanları iş parçacığı oluşturma iş yükü dağıtımı(iş paylaşımı), veri ortam yönetimi, iş parçacığı senkronizasyonu, kullanıcı seviyeli çalışma zamanı rutinleri ve ortam değişkenleri için yapılardır.
C/C++' ta OpenMP #pragma etiketi kullanılır. OpenMP özel pragmalar aşağıda listelenmiştir.
İş Parçacığı Oluşturma
omp parallel pragma paralelleştirilmiş yapı içerisinde kapanmış işi gerçekleştirmek için ek iş parçacıklarını çapraz dağıtmak için kullanılır. Orijinal iş parçacığı ID=0 olan ana iş parçacığı olarak gösterilir.
Örnek (C program): Çoklu iş parçacığı kullanarak "Merhaba Dünya" yazdırmak.
#include <stdio.h>
int main(void)
{
#pragma omp parallel
printf("Merhaba, dünya.\n");
return 0;
}
GCC kullanarak derlemek için -fopenmp bayrağı kullanılır:
$gcc -fopenmp merhaba.c -o merhaba
' iş parçacıklı ve 2 çekirdekli bilgisayar üzerindeki çıktı.
Merhaba, dünya.
Merhaba, dünya.
Bununla birlikte çıktı yarış durumları sebebiyle 2 iş parçacığının standart çıktıyı paylaşmasından dolayı bozulmuş bir şekilde alınabilir.
Merhaba, düMerha, düünya
nya.
İş Paylaşma Yapıları
İş parçacıklarının birinin veya tamamına birbirinden bağımsız iş atamak için aşağıdakiler kullanılır.
- omp for veya omp do: iş parçacıkları arasında döngü iterasyonlarını paylaştırmak için kullanılır.Döngü yapıları olarak da adlandırılır.
- sections: sıralı atama yapılır fakat farklı iş parçacıklarına bağımsız kod blokları atanır
- single: sadece bir iş parçcağının yürüttüğü bir kod bloğu belirlenir, programın sonunda bir bitiş yeri gösterir
- master: single gibidir, ama kod bloğu ana işparçacığı tarafından yürütülür ve program sonunda bir bitiş yeri gösterilmez.
Örnek: paralel olarak büyük bir diziye iş parçacıkları kullanarak ilk değerleri vermek
int main(int argc, char *argv[]) {
const int N = 100000;
int i, a[N];
#pragma omp parallel for
for (i = 0; i < N; i++)
a[i] = 2 * i;
return 0;
}
OpenMP Cümlecikleri
OpenMP paylaşımlı bellek programlama modeli olduğu için OpenMP kodu içerisindeki çoğu değişken varsayılan olarak tüm iş parçacıklarına görünür, ama bazen özel değişkenlerin yarış durumlarından kaçınması gereklidir ve seri bölge ile paralel bölge arasındaki değerlerin işlenebilmesi için veri ortam yönetimi veri paylaşım özellik cümlecikleri olarak tanıtılmıştır. Bu cümlecikler OpenMP direktiflerine eklenir
Veri paylaşımı özelliği cümlecikleri
- shared: paralel bölge ile birlikte veri paylaşılır. Paylaşımın anlamı tüm işparçacıkları tarafından erişilebilir ve görülebilirdir. Varsayılan olarak iş paylaşım bölgesindeki tüm değişkenlerin döngü iterasyon sayacı dışında hepsi paylaşılır
- private: paralel bölge ile birlikte veri her bir iş parçacığına özeldir. Bunun anlamı her bir iş parçacığının yerel bir kopyaya sahip olacağı ve o değişkeni geçici olarak kullanacağıdır. Bir özel değişken ilklendirilmez ve değeri paralel bölge dışında kullanılmaz. Varsayılan olarak döngü iterasyon sayacı özeldir.
- default: programcıya Fortran için none, C/C++ için none,firstprivate, private, shared paralel bölgeleri için veri alanına müdahele etmesine izin verir. none seçeneği programcının veri paylaşımlı özellik cümleciğini kullanarak paralel bölge içerisindeki her bir değişkeni tanımlamasına zorlar.
- firstprivate: orijinal değeri ilklendirme haricindeprivate gibidir. .
- lastprivate: yapıdan sonra güncellenen orijinal değer haricinde private gibidir.
- reduction: yapıdan sonra tüm iş parçacıklarının işe katılmasının güvenli bir yöntemidir.
Senkronizasyon cümlecikleri
- critical: seçili kod bloğu bir kerede sadece bir iş parçacığı tarafından yürütülecektir ve çoklu iş parçacıkları tarafından eş zamanlı yürütlmez. Bu genelde yarış durumlarından veri paylaşımını korumak için kullanılır
- atomic: Bellek güncellenmesi otomatik olarak işletilir. Tüm ifadeyi atomic yapmaz, sadece bellek güncellenmesi atomiktir. Bir derleyici daha iyi performans için critical kullanmak yerine özel bir donanım komutu kullanabilir.
- ordered: Yapı bloğu bir sıra içerisinde yürütülür. Bu sıra seri döngü içerisinde yürütülen iterasyonlar ile yapılır.
- barrier: her bir iş parçacığı bir takımın diğer iş parçacıklarının tümü bu noktaya ulaşıncaya kadar beklerler. İş paylaşımı yapısı, yapını sonunda örtülü bir bariyer senkronizasyonuna sahiptir.
- nowait: Takım içerisindeki tüm iş parçacıklarının bitirmesini beklemeden işleyebilirler. Bu cümleciğin yokluğunda iş parçacıkları iş paylaşım yapısının sonunda bir bariyer senkronizasyonu ile karşılaşır.
Zamanlama cümlecikleri
- schedule(type, chunk): iş paylaşımlı yapı do-loop veya for-loop ise bu kullanışlıdır. İşpaylaşımı içerisindeki iterasyonlar bu cümlecik kullanılarak tanımlanan zamanlama metoduna göre iş parçacıklarına atanır. Zamanlamanın 3 tipi:
- static: Burada tüm iş parçacıkları döngü iterasyonlarını yürütmeden önce iterasyonlara tahsis edilirler. Iterasyonlar varsayılan olarak eşit bir şekilde iş parçacıkları arasında paylaştırılır. Bununla birlikte bir chunk parametresi için bir tam sayı belirlemek özel bir iş parçacığına bitişik iterasyonlar tahsis edecektir.
- dynamic: Burada, iterasyonların bazıları daha az sayıda iş parçacıklarına tahsis edilir. İlk kez özel bir iş parçacığı tahsis edildiği iterasyonu tamamlarsa iş parçacığı kalan iterasyonlardan 1 değerini elde etmek için geri döner. chunk parametresi bir kerede bir iş parçacığına tahsis edilecek bitişik iterasyonların sayısını tanımlar.
- guided: Çok sayıda bitişik iterasyon parçaları dinamik olarak her bir iş parçacığına tahsis edilir. Parça boyutu chunk parametresi içinde belirlenen minimum boyuta başarılı bir şekilde tahsis edilmesiyle üssel olarak azalır.
IF Kontrol
- if: Ancak ve ancak bir durum bir görevi paralelleştirmek için iş parçacığı ile karşılaşılmasına sebep oluyorsa görev paralelleştirilir. Diğer durumda kod bloğu seri olarak yürütülür.
İlklendirme
- firstprivate: Veri her bir iş parçacığına özeldir ama değişkenin değerini kullanan ilklendirme ana iş parçacığından aynı isim kullanılarak yapılır.
- lastprivate: Veri her bir iş parçacığına özeldir. Bu özel verinin değeri paralelleştirilmiş döngüdeki iterasyon son iterasyon ise paralel bölgenin dışındada aynı ismi kullanarak global değişkene kopyalanacaktır. Değişken hem firstprivate hem de lastprivate olabilir.
- threadprivate: Veri global bir veridir ama çalışma zamanında her bir paralel bölge içerisinde özeldir. threadprivate ve private arasındaki fark threadprivate ile ilişkilendirilmiş global alandır ve paralel bölgeler içerisinde korunmuş değerdir.
Veri kopyalama
- copyin: private değişkenler içinfirstprivate gibidir , threadprivate değişkenleri ilklendirilmez. Taki karşılık gelen global değişkenlerden değerler geçirilmek için copyin kullanılana kadar.copyout gereksizdir çünkü threadprivate değişkeninin değeri tüm programın yürütümü boyunca korunur.
- copyprivate: bir iş parçacığı üzerindeki özel nesnelerden takım içerisindeki diğer iş parçacıkları üzerinde karşılık gelen nesnelere veri değerlerinin kopyalanmasını desteklemek için single ile birlikte kullanılır.
indirgeme
- reduction(operator | intrinsic : list): değişken her bir iş parçacığı içerisinde yerel bir kopyaya sahiptir, fakat yerel kopyaların değerleri global paylaşımlı değişken içerisine indirgenmiş olacaktır. Bu eğer özel bir işlem(özel bir cümlecik için operatördeki belirlenmiş) iteratif olarak veritipi üzerindeyse kullanışlı olacaktır. Böylece özel iterasyondaki değeri onun önceki iterasyondaki değerine bağlıdır. Temel olarak operasyonel arttırma paralelleştirmeye yol açan adımlardır. Fakat iş parçacıkları toplanır ve veritipi güncellenmeden önce beklerler. Ardından sırasıyla veritiplerindeki artırımlar yarış durumlarından kaçınmak için gerçekleştirilir. Bu paralelleştirme içerisindeki fonksiyonların sayısal birleştirmelerini ve diferansiyel denklemlerini gerektirecektir.
Diğerleri
- flush: Bu değişkenin değeri paralel bölümün dışarısındaki bu değeri kullanmak için belleğe, bellekteki yazmaçtan sağlanır
- master: Sadece ana iş parçacığı tarafından yürütülür hiçbir örtülü bariyer yoktur. Diğer takım üyelerinin erişmesi gerekmez.
Kullanıcı seviyesi çalışma rutinleri
İş parçacıklarının sayısını değiştirmek ve kontrol etmek, eğer yürütüm paralel bölge içerisinde ise tespit etmek ve o an sistemde kaç tane işlemcinin çalıştığını belirlemek için kullanılır.
Ortam Değişkenleri
OpenMP uygulamalarının yürütme özelliklerini değiştirmek için kullanılan bir metottur. Kontrol döngü iterasyonlarını zamanlamak, iş parçacıklarının sayılarını varsayılan yapmak için kullanılır. Mesela OMP_NUM_THREADS bir uygulama için işparçacıklarının sayılarını belirlemede kullanılır.
Örnek programlar
Bu bölümde bazı örnek programlar üstte açıklanan kavramları göstermek için verilmiştir.
Merhaba Dünya
parallel, private ve barrier direktiflerini örnekleyen temel bir program ve omp_get_thread_num ve omp_get_num_threads fonksiyonlarını kullanır.
C
Bu C programı -fopenmp bayrağıyla birlikte gcc 4.4 kullanılarak derlenmiştir.
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
int main (int argc, char *argv[]) {
int th_id, nthreads;
#pragma omp parallel private(th_id)
{
th_id = omp_get_thread_num();
printf("Hello World from thread %d\n", th_id);
#pragma omp barrier
if ( th_id == 0 ) {
nthreads = omp_get_num_threads();
printf("There are %d threads\n",nthreads);
}
}
return EXIT_SUCCESS;
}
C++
Bu C++ programı GCC: gcc -Wall -fopenmp test.cpp -lstdc++ kullanılarak derlenmiştir.
#include <iostream>
using namespace std;
#include <omp.h>
int main(int argc, char *argv[])
{
int th_id, nthreads;
#pragma omp parallel private(th_id) shared(nthreads)
{
th_id = omp_get_thread_num();
#pragma omp critical
{
cout << "Hello World from thread " << th_id << '\n';
}
#pragma omp barrier
#pragma omp master
{
nthreads = omp_get_num_threads();
cout << "There are " << nthreads << " threads" << '\n';
}
}
return 0;
}
Fortran 77
Bu da Fortran 77 versiyonu.
PROGRAM HELLO
INTEGER ID, NTHRDS
INTEGER OMP_GET_THREAD_NUM, OMP_GET_NUM_THREADS
C$OMP PARALLEL PRIVATE(ID)
ID = OMP_GET_THREAD_NUM()
PRINT *, 'HELLO WORLD FROM THREAD', ID
C$OMP BARRIER
IF ( ID .EQ. 0 ) THEN
NTHRDS = OMP_GET_NUM_THREADS()
PRINT *, 'THERE ARE', NTHRDS, 'THREADS'
END IF
C$OMP END PARALLEL
END
Fortran 90 serbest biçim
Bu da Fortran 90 serbest biçim versiyonu.
program hello90
use omp_lib
integer:: id, nthreads
!$omp parallel private(id)
id = omp_get_thread_num()
write (*,*) 'Hello World from thread', id
!$omp barrier
if ( id == 0 ) then
nthreads = omp_get_num_threads()
write (*,*) 'There are', nthreads, 'threads'
end if
!$omp end parallel
end program
C/C++ İş Paylaşımı Yapılarındaki Cümlecikler
Bazı OpenMP cümleciklerinin uygulaması bu bölümde basit örneklerle gösterilmiştir. Aşağıdaki kod parçası a dizisinin elemanları üzerinde basit bir operasyon işleterek b dizisinin elemanlarını günceller. Paralelleştirme OpenMP direktifi #pragma omp tarafından yapılır. Görevlerin zamanlanması dynamictir. İterasyon sayaçları j ve k'nın özel olmak zorunda olduğunu ve ilkel iterasyon sayacı i'nin varsayılan olarak özel olduğunu görebilirsiniz. i boyunca çalışan görevler çoklu iş parçacıkları arasında paylaştırılmıştır ve her iş parçacığı j ve k'nın kendi versiyonlarını oluştururlar. Bu yüzden tüm görevin tahsisini yapmak ve b dizisinin tahsis edilmiş parçasını güncellemek diğer iş parçacıklarıyla aynı zamanda yapılır.
#define CHUNKSIZE 1 /*defines the chunk size as 1 contiguous iteration*/
/*forks off the threads*/
#pragma omp parallel private(j,k)
{
/*Starts the work sharing construct*/
#pragma omp for schedule(dynamic, CHUNKSIZE)
for(i = 2; i <= N-1; i++)
for(j = 2; j <= i; j++)
for(k = 1; k <= M; k++)
b[i][j] += a[i-1][j]/k + a[i+1][j]/k;
}
Diğer kod parçacığı indirgeme cümleciğinin indirgenmiş toplamlarını hesaplamak için yaygın kullanımını gösterir. Burada OpenMp direktifleri ve indirgeme cümlecikleri kullanarak paralelleştirdiğimiz for döngüsünü içindeki i ile birlikte tüm a dizisinin elemanlarını ekliyoruz. Zamanlama static sürdürülür.
#define N 10000 /*size of a*/
void calculate(long *); /*The function that calculates the elements of a*/
int i;
long w;
long a[N];
calculate(a);
long sum = 0;
/*forks off the threads and starts the work-sharing construct*/
#pragma omp parallel for private(w) reduction(+:sum) schedule(static,1)
for(i = 0; i < N; i++)
{
w = i*i;
sum = sum + w*a[i];
}
printf("\n %li",sum);
Üstteki kodun gerçekleştirimin bir dengi her bir iş parçacığı için yerel sum değişkeni kullanmaktır("loc_sum") ve sürecin sonunda global sum değişkeninin güncellenmesini korumaktır. Aşağıda açıklandığı gibi bu koruma önemlidir
...
long sum = 0, loc_sum;
/*forks off the threads and starts the work-sharing construct*/
#pragma omp parallel private(w,loc_sum)
{
loc_sum = 0;
#pragma omp for schedule(static,1)
for(i = 0; i < N; i++)
{
w = i*i;
loc_sum = loc_sum + w*a[i];
}
#pragma omp critical
sum = sum + loc_sum;
}
printf("\n %li",sum);
Gerçekleştirimler
OpenMP birçok ticari derleyiciler içerisinde gerçekleştirilir. Mesela Visual C++ 2005,2008 ve 2010 OpenMp destekler. Aynı zamanda Intel Parallel Studio, Oracle Solaris Studio derleyicileri ve araçları OpenMp'nin son versiyonunu destekler. Fortran, C/C++ derleyicileri de OpenMP 2.5 destekler. GCC OpenMp'yi 4.2 versiyonundan beri desteklemektedir.
OpenMP 3.0 gerçekleştirimini destekleyen derleyiciler:
- GCC 4.3.1
- Nano derleyiciler
- Intel Fortran and C/C++ versions 11.0 and 11.1 derleyiciler, Intel C/C++ and Fortran Composer XE 2011 and Intel Parallel Studio.
- IBM XL C/C++ derleyici
- Sun Studio 12'nin, OpenMP 3.0'ın tüm gerçekleştirimlerini içeren bir güncellemesi vardır.
Birçok derleyici OpenMP 3.1'i destekler:
- GCC 4.7
- Intel Fortran and C/C++ derleyiciler.
Artılar ve Eksiler
Artılar
- Taşınabilir çok iş parçacıklı kod (C/C++ ve diğer dillerde, bir tanesi tipik olarak çoklu işparçacığını elde etmek için bir platform çağırır)
- Basittir. MPI'ın yaptığı gibi mesaj geçirmeyle uğraşmaya gerek yoktur.
- Veri planı ve ayrılması direktifler tarafından otomatik olarak yönetilir.
- Artımlı paralellik: bir kerede bir programın bir kısmında çalışabilir. Kodda fazla bir değişikliğe ihtiyaç yoktur.
- Hem seri hem de paralel uygulamalar için birleştirilimiş kod:OpenMP yapıları seri derleyiciler kullanıldığı zaman derleyiciler tarafından yorumlar olarak anlaşılır.
- Seri kod ifadeleri gerekmez. Genel olarak OpenMP ile paralelleştirildiğinde bu beklenmedik hatalarla karşılaşma ihtimalini azaltır.
- Hem doğrudan hem de iyileştirilmiş paralelleştirme mümkündür.
Eksiler
- Yarış durumları ve senkronizasyon hatalarıyla karşılaşma riski çok fazladır.
- Şu anda sadece verimli bir şekilde paylaşımlı bellek platformunda çalışır.
- Derleyicinin OpenMP'yi desteklemesini gerektirir.
- Ölçeklenebilirlik bellek mimarisi ile sınırlıdır.
- karşılaştır ve yer değiştir için destek vermez
- hata yönetimine güvenilirlik azdır.
- İş parçacığı işlemci eşleştirmeyi kontrol etmek için iyileştirilmiş mekanizma eksiktir.
- GPU üzerinde kullanılmaz.
- Kazara yanlış paylaşımlı kod yazma olasılğı yüksektir.
- Genelde çoklu iş parçacığı hala faydası olmayan yerlerde kullanılmaktadır.
Kriterler
Kullanıcı çalışması için OpenMP kriter alanları mevcuttur..
- NAS parallel benchmark28 Ekim 2011 tarihinde Wayback Machine sitesinde arşivlendi.
- OpenMP validation suite
- OpenMP source code repository1 Mayıs 2013 tarihinde Wayback Machine sitesinde arşivlendi.
- EPCC OpenMP Microbenchmarks
Online dokümanlar
- Tutorial18 Eylül 2008 tarihinde Wayback Machine sitesinde arşivlendi. on llnl.gov
- Reference/tutorial page31 Ocak 2011 tarihinde Wayback Machine sitesinde arşivlendi. on nersc.gov
- Tutorial in CI-Tutor20 Aralık 2011 tarihinde Wayback Machine sitesinde arşivlendi.
Bunları da inceleyebilirsiniz
- Cilk ve Intel Cilk Plus
- Message Passing Interface
- Concurrency (computer science)
- Parallel computing
- Parallel programming model
- POSIX Threads
- Unified Parallel C
- X10 (programming language)
- Parallel Virtual Machine
- Bulk synchronous parallel
- Grand Central Dispatch - C, C++, ve Objective-C için Apple tarafından geliştirilmiş karşılaştırılabilir teknoloji
- Partitioned global address space
- GPGPU
- CUDA - Nvidia
- AMD FireStream
- Octopiler
- OpenCL - Apple, Nvidia, Intel, IBM, AMD/ATI ve diğer pek çoğu tarafından standart desteklidir
- OpenACC - openMP'ye birleştirilmesi planlanan GPU hızlandırması için bir standart
- Derin öğrenme yazılımlarının karşılaştırılması
Yardımcı Kaynaklar
- Quinn Michael J, Parallel Programming in C with MPI and OpenMP McGraw-Hill Inc. 2004. ISBN 0-07-058201-7
- R. Chandra, R. Menon, L. Dagum, D. Kohr, D. Maydan, J. McDonald, Parallel Programming in OpenMP. Morgan Kaufmann, 2000. ISBN 1-55860-671-8
- R. Eigenmann (Editor), M. Voss (Editor), OpenMP Shared Memory Parallel Programming: International Workshop on OpenMP Applications and Tools, WOMPAT 2001, West Lafayette, IN, USA, July 30–31, 2001. (Lecture Notes in Computer Science). Springer 2001. ISBN 3-540-42346-X
- B. Chapman, G. Jost, R. van der Pas, D.J. Kuck (foreword), Using OpenMP: Portable Shared Memory Parallel Programming. The MIT Press (October 31, 2007). ISBN 0-262-53302-2
- Parallel Processing via MPI & OpenMP, M. Firuziaan, O. Nommensen. Linux Enterprise, 10/2002
- MSDN Magazine article on OpenMP
- SC08 OpenMP Tutorial (PDF) - Hands-On Introduction to OpenMP, Mattson and Meadows, from SC08 (Austin)
- OpenMP 3.0 Summary Card30 Nisan 2013 tarihinde Wayback Machine sitesinde arşivlendi. (PDF)
- Parallel Programming in Fortran 95 using OpenMP (PDF)
Harici Bağlantılar
- Çanakkale OnSekiz Mart Üniversitesi11 Haziran 2020 tarihinde Wayback Machine sitesinde arşivlendi.
- Çanakkale OnSekiz Mart Üniversitesi Bilgisayar Mühendisliği22 Ekim 2013 tarihinde Wayback Machine sitesinde arşivlendi.
- Resmî site, includes the latest OpenMP specifications, links to resources, and a lively set of forums where questions about OpenMP can be asked and are answered by the experts and implementors.
- GOMP22 Mayıs 2013 tarihinde Wayback Machine sitesinde arşivlendi. is GCC's OpenMP implementation, part of GCC
- IBM Octopiler29 Ocak 2009 tarihinde Wayback Machine sitesinde arşivlendi. with OpenMP support
- Blaise Barney, Lawrence Livermore National Laboratory site on OpenMP18 Aralık 2019 tarihinde Wayback Machine sitesinde arşivlendi.
- ompca, an application in REDLIB project for the interactive symbolic model-checker of C/C++ programs with OpenMP directives23 Haziran 2013 tarihinde Wayback Machine sitesinde arşivlendi.
Kaynakça
- http://openmp.org/wp/about-openmp/ About the OpenMP ARB and OpenMP.org
- http://openmp.org/wp/2011/07/openmp-31-specification-released/ OpenMP 3.1 Specification Released
- http://openmp.org/wp/openmp-compilers/ OpenMP Compilers
| Genel | |
|---|---|
| Koşutluk düzeyleri | |
| İzlekler | Üst izlekleme · Yüksek izlekleme |
| Kuram | |
| Ögeler | |
| Eşgüdüm | Çoklu işleme · Çoklu izlekleme · Bellek tutarlılığı · Ön bellek tutarlılığı · Engel · Eşzamanlılaştırma · Aşamalı uygulama denetimi |
| Programlama | |
| Donanım | Flynn Sınıflandırması (SISD • SIMD • MISD • MIMD) · Boru hattı yöntemi · Çoklu işleme (Bakışımlı · Bakışımsız) · Bellek (NUMA · COMA · Dağıtık · Paylaşımlı · Dağıtık paylaşımlı) · SMT MPP · Sayılüstü · Dizi işlemcisi · Süper bilgisayar · Beowulf |
| APIler | |
| Sorunsallar | Olağanüstü koşutluk · Büyük Sorun · Yazılım durağanlığı · Ölçeklenebilirlik · Yarışma koşulları · Deadlock · Gerekirci algoritma |
| |
